4.5 KiB
Distributed Tracing
Abstract
This document details why implementing distributed tracing can help us troubleshoot production issues and the steps needed to implement.
Background
Distributed tracing enables the ability to visualize how operations are executed in sequence and in parallel within service boundaries and across services which can greatly help troubleshoot development and production issues. Distributed tracing allows you to begin troubleshooting from a high level instead of the common approach of starting from log files or stack traces which can be less informative to operational staff. Traces can begin from a user client perspective all the way down to the database tier while enabling any process operation to attach metadata along the traced path.
For example, a typical use case of distributed tracing in a web application is that a trace begins at a web browsers HTTP request, attaches pertinent header and request information which propagates to the API service backend and eventually reaches the database layer which attaches SQL query metadata. If anything in this trace behaves slowly or throws an error you can use tools like Zipkin, Jaeger, DataDog or any OpenTracing compatible visualization tool to search and analyze what happened within a trace (request).
Design
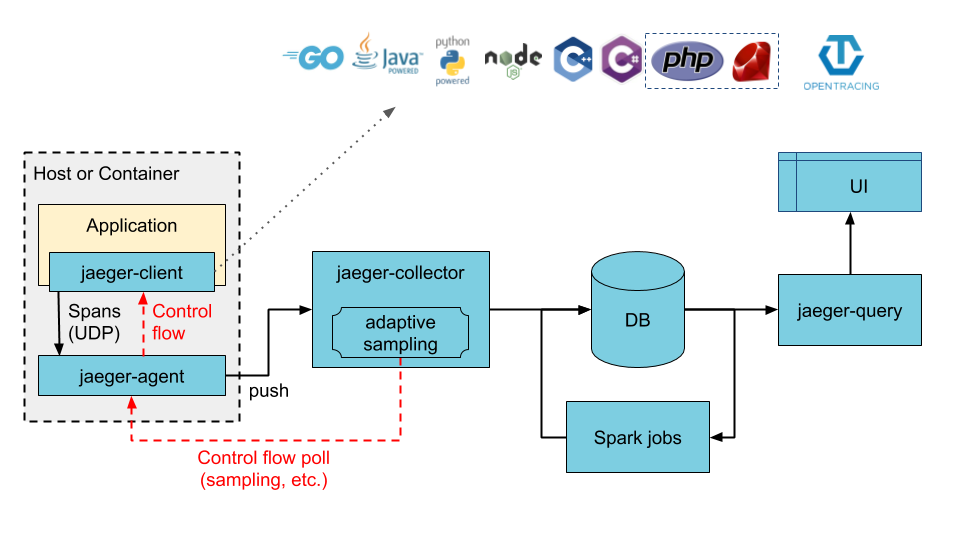 Figure 1. Typical Jaeger architecture.
Figure 1. Typical Jaeger architecture.
We propose to send Jaeger compatible traces over the UDP jaeger.thrift compact thrift protocol as documented here on port 6831 to the jaeger-agent process similar to how monkit currently sends metrics to the statsreceiver over UDP.
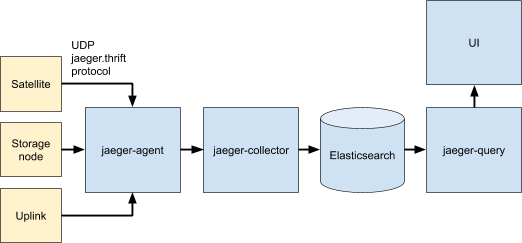 Figure 2. Proposed monkit + jaeger architecture.
Figure 2. Proposed monkit + jaeger architecture.
Rationale
Tracing protocol between monkit traces and Jaeger We propose using the jaeger-agent jaeger.thrift compact protocol because after some experimentation it was discovered Jaeger and Zipkin no longer support the protocol implemented from OpenZipkin 0.12 that the monkit-zipkin project implements.
Jaeger storage database
There are 2 possible production quality storage databases supported by Jaeger. Cassandra and Elasticsearch. The pros and cons between the two drastically differ so we should align what we deploy with what we need.
Cassandra Pros
- Better scale out than Elasticsearch.
- Better reliability than Elasticsearch.
Cassandra Cons
- Slower queries than Elasticsearch.
- Some queries in Jaeger UI are not even possible using Cassandra. For example, Cassandra doesn't support searching on duration and tags at the same time.
Elastic search Pros
- Faster queries than Cassandra.
- Richer query support. Some queries are only possible in Elasticsearch.
Elastic search Cons
- More unreliable than Cassandra. Leader flapping, unavailable more often and generally harder to keep happy.
Implementation
- Update monkit-zipkin to use monkit-v3.
Also add support for monkit v3 tags to OpenTracing tags. - Implement JaegerThriftCompactUDPCollector protocol in monkit-zipkin.
There is an existing monkit-zipkin project that integrates sending monkit traces to Zipkin but it uses a Zipkin protocol that has been deprecated and doesn’t exist any longer. However this project has a lot of what we need to implement a Jaeger compatible protocol. We could make a version of this code in udp.go to send Jaeger trace messages using a supported UDP protocol. There is already a golang implementation found here that maybe we can use. - Implement optional support for running Jaeger with storj-sim.
- Implement monkit-zipkin collector into the Satellite startup code.
- Implement monkit-zipkin collector into the Storage Node startup code.
- Implement monkit-zipkin collector into the uplink CLI app startup code.
Wrapup
[Who will archive the blueprint when completed? What documentation needs to be updated to preserve the relevant information from the blueprint?]
Open issues
- Jaeger ingestor.
Jaeger has a jaeger-ingestor service that can use Kafka to offer higher reliability and reduce risk of dropping traces during upgrades of the database or prevent database stalls from causing dropped traces. Running Kafka is not trivial to run reliably. Do we need this level of reliability for the additional operational cost? - Deployment.
It is unclear to us how we plan to deploy Jaeger and all of its dependencies. We will need the following infrastructure related to Jaeger deployed in our environments.- Jaeger-agent.
- Jaeger-collector.
- Jaeger-query.